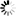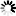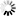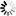

锥形钢管|面包管|六角钢管专营 长期备有各种规格的无缝钢管、高压锅炉管、流体管、结构管、化肥专用管以及德美日意进口的合金钢管等。常年保持库存1万吨左右,年销量售额过亿元。所售产品均执行国家标准,适用于工程、煤矿、纺织、电力、锅炉、机械、军工等各个领域。我们以良好的信誉、优质的产品、雄厚的实力、低廉的价格享誉全国30多个省、市、自治区、直辖市,产品深得用户依赖。 目前拥有一条国内领先的800×800×30mm大型冷弯空心型钢生产线,1600mm纵剪生产线一条。其中F200采用国际最先进的直接成方、矩技术,可生产方管30×30mm-800×800mm;矩管20×40-800×1200mm;壁厚1.5-30mm,年产量40万吨,也可为客户定做各类异型管、镀锌扇形管http://www.tjdxtyg.com/非标扇形管、三角钢管、六角钢管、八角钢管、面包管、锥形钢管,产品广泛用于钢结构、机械制造、建筑工程、汽车制造、造船、电力等诸多行业。主要产品规格为¢25—¢108mm壁厚¢2—¢20mm钢管,还有¢273—¢720mm壁厚¢6—¢50mm钢管各大无缝钢管厂生产的无缝钢管,合金钢管,结构流体管,高压锅炉管以及锥形钢管,面包管,六角钢管,锥形管,扇形管等,欢迎订购。
公司网址: http://www.tjyixingguan.com/
联系我时,请说是在铭竟信息网看到的,谢谢!



 已通过身份证认证
已通过身份证认证  已通过营业执照认证
已通过营业执照认证 